作为适应性免疫的关键细胞效应物,T和B淋巴细胞利用专门的抗体来识别抗原,响应和中和各种外在威胁。这些受体(B淋巴细胞中的免疫球蛋白,T淋巴细胞中的T细胞受体)具有令人难以置信的序列变异.
免疫组测序
背景知识
在脊椎动物中🐒🐘, T/B细胞是适应性免疫系统的两大细胞群,在抗体的产生, 和免疫反应中具有非常重要的地位. 抗体多样性是免疫系统的重要特性。自然界的抗原种类极多,每种抗原还有不同的抗原决定簇,因此具有多种特异性的免疫球蛋白分子的种类也必定是极其众多的,可以有几百万种。可是,脊椎动物基因组内所有的基因总共不过几万个左右。因此,决不可能有那么多的免疫球蛋白基因去编码每一种特定的免疫球蛋白分子。
所以为了产生足够多样的抗体, 脊椎动物🐻和人🤰的淋巴细胞在其成熟过程中会发生抗体基因的重排, 其目的是为了增加特异性识别抗体的多样性.
但是在细胞高度特异和分化的动物, 基因发生重拍就意味着基因结构和编码产物发生变化. 这是一个非常危险⛔的
那么就要认真了解下, 生命是如何在这样的钢丝线上走的又稳又快. 🐟 和 🐻 掌兼得的. 又如何通过免疫组库测序(IR-seq)来进行研究.
免疫球蛋白的基因重排
首先是, 脊椎动物🐻淋巴细胞在其细胞成熟过程中会发生基因的重排已经是普识. 利根川进(Tonegawa S) 👨, 还因为揭示了免疫基因的重排基因获得了1987年的诺贝尔生理与医学奖🏆.
1987年,利根川教授因“发现抗体多样性的遗传学原理”成为首位亚洲/日本籍诺贝尔生理学或医学奖得主,也是免疫学领域“独得诺贝尔奖”的唯一一人。
大家都知道一个浆细胞只产生一种抗体分子, 而一个抗体分子有两条轻链(L)和两条重链(H)组成, 分别由三个独立的基因簇所编码, 其中两个编码轻链kappa链和 lamada链. 而另一个编码重链. 不同物种的编码基因簇所在染色体是不一致的.
编码轻链的基因簇上分别有L, V, J,C 四类基因片段.其中 L前导片段(leader segment), V 是可变片段(variable segment) ,J代表链接片段(jioning segement), C代表恒定片段(constant segement).
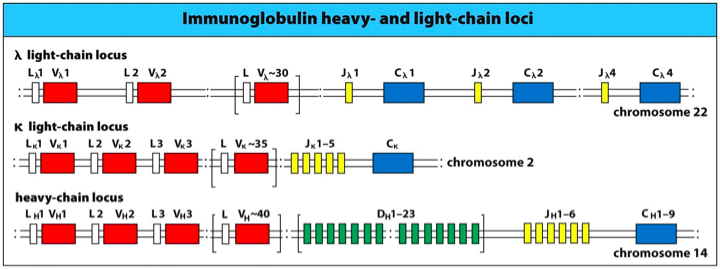
反观重链, 会有五类基因片段, 多出来的是 D 多样性片段 , 同时,在重链的 J和 C 片段之间存在增强子.其中需要注意的一点是, 重链的C恒定区具有的片段就是决定抗体亚型的区域. 比如人的第14个染色体上的重链家族, 有八个C片段. (其中两个是假蛋白)这些片段决定抗体的亚型, 是
抗体基因的重排机制 {# section-01}
在胚胎细胞中,V、J、D和C基因是分散排列的,在B细胞发育成熟过程中,基因组中组成免疫球蛋白分子的各个基因开始发生重排,在轻链上, V区基因发生V—J重排, 而在重链上先是D片段和J片段相连, 然后V片段链接上D-J片段, 形成V-D-J复合体. 最后都会和C基因链接, 完成基因重排. 最终会转录成mRNA前体, 翻译成蛋白. 然后重链和轻链复合, 最后完成加工并运输锚定在膜上.
这里有一点需要注意的是, 重链就一个, 但是轻链有两个kappa链和 lamada链. 只有kappa链重组失败, 才会启动lamada链与重链结合. 所以大部分的抗体都是kappa链链, 少部分是 lamada链. 同时, 一个浆细胞只能产生一种抗体, 但是浆细胞是二倍体. 不论是重链还是轻链都是有等位基因簇存在的. 因此, 免疫基因的重排是等位基因排斥的. 只要有一个等位基因发生基因重排, 那另一个等位基因的重排就会收到抑制. 轻链还是会出现同型性排斥, 就是一旦某个等位基因的kappa链链发生重组, 不仅另一个等位基因的重排,甚至 lamada链的两个等位基因的重排都会收到抑制.
神奇的生命体, 不过计算哪里有问题, 也就1000天啊, 小鼠活不了三年???
我自己小声BB
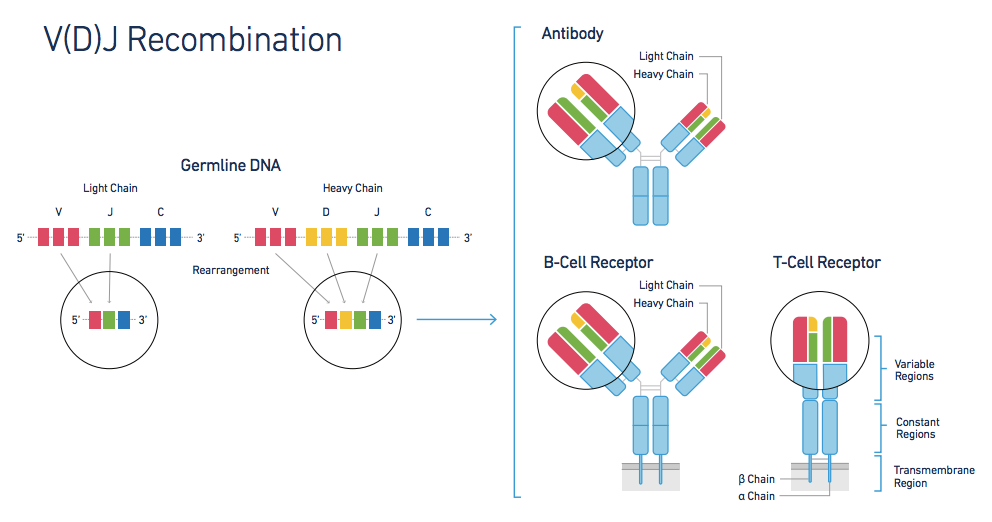
由于抗体基因还可以通过
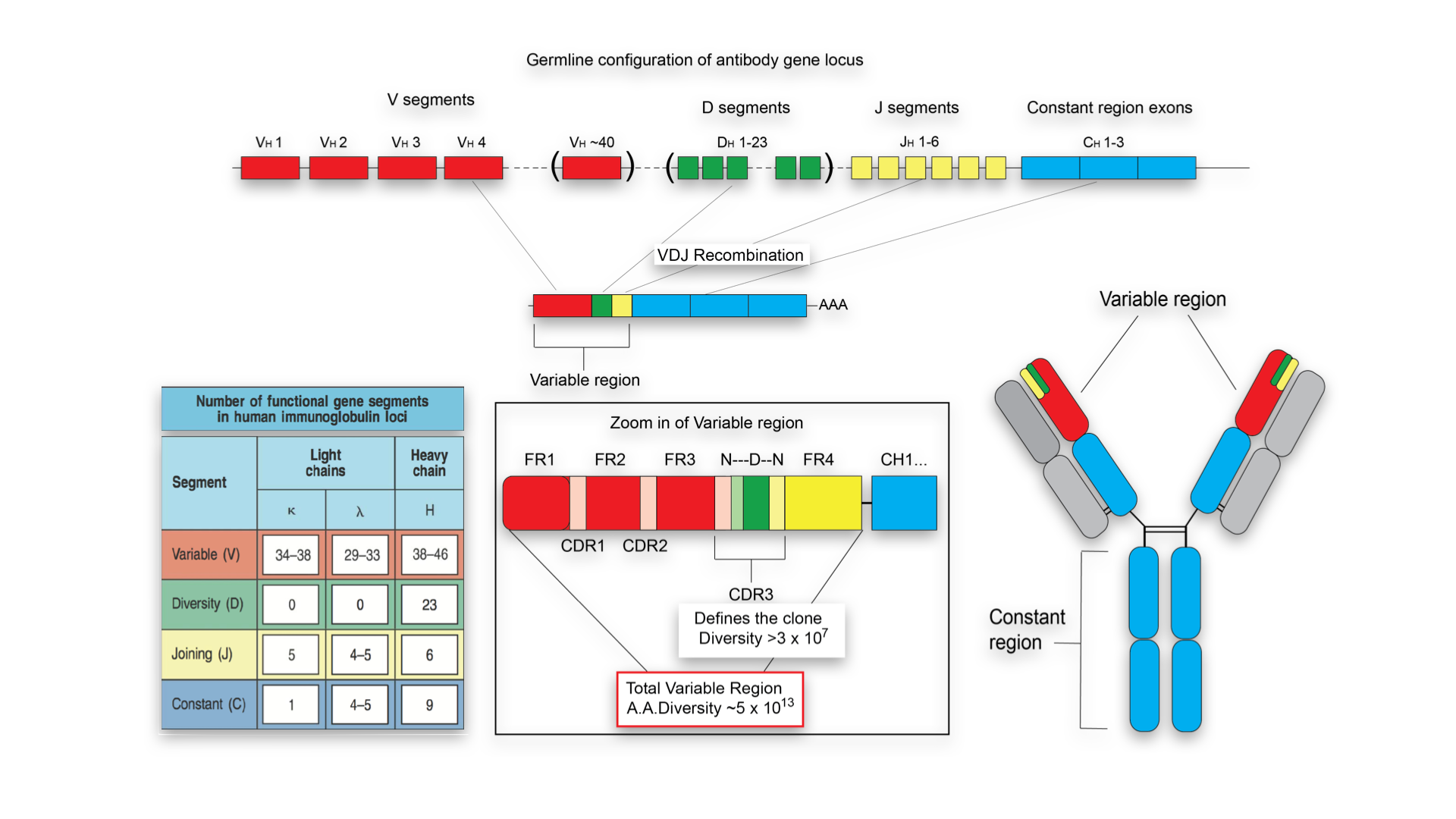
免疫基因的重排调控
如此频繁的基因重组, 虽然能够为自身的免疫力, 提供大量并且 特异性的识别抗体分子, 但是生命是一种稳态. 如此频繁的
其实, 在V-D-J等基因片段发生重组的部位, 是有保守型的特异性核苷酸序列, 被称为重组信号序列(recombinnation signal sequence,RSS). RSS主要有一个七寡核苷酸链CACAGTG,和一个九寡核甘酸链ACAAAAACC。RSS之间的间隔长度也是固定, 分别为12bp和23bp长短。这种“七聚体―间隔序列―九聚体”结构即为重组信号序列。在重组酶识别和作用下,带有12bp间隔序列RSS的基因片段只能和带有23bp间隔序列的片段相结合而发生重排,被称为12-23规则,它保证了基因片段连接的正确性。
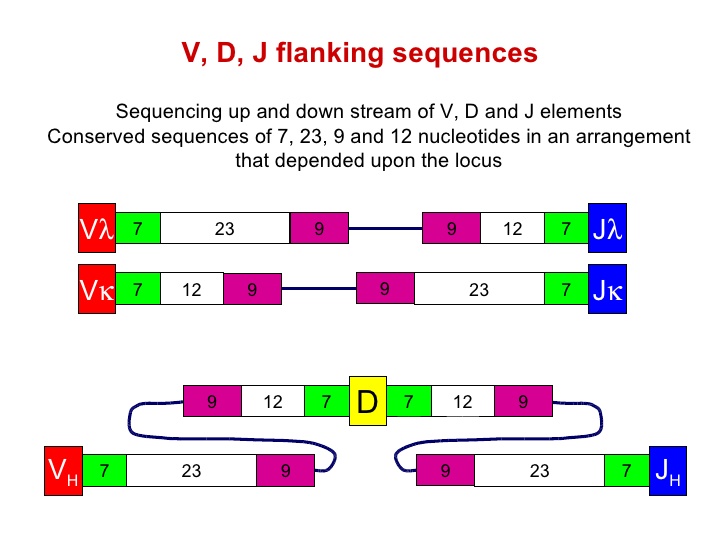
从图中可以看到, 不论是两中轻链的V-J结合, 还是重链的V-D-J结合, 都是需要这样的7-12-9,和9-23-7这样的序列结构.
基因片段重组的酶,包括RAG蛋白、末端脱氧核苷酸转移酶(TdT)以及参与修复DNA双链断端的多种酶(如内切酶、外切酶、DNA合成酶等)。重组激活基因(RAG)编码的蛋白称为RAG-1和RAG-2。RAG-1识别七核苷酸和九核苷酸的信号, 招募RAG-2形成复合物行驶内切酶的作用, 这个过程只发生在T、B细胞不成熟阶段。因此, 也只有前B细胞和前T细胞中才能发生免疫基因的重排,而在成熟的T、B细胞中则无重排发生.
毕竟第一次基因重排是发生在分化成熟的过程中的 , 第二次基因重排改变的是C区, 也就是免疫分子的亚型, 不改变抗原特异性. 只是为了分化成高产量的奖细胞.
RSS的切割和链接保证了基因片段连接的方向性和正确性。但是这个切割形成的DNA末端并不是常见的断裂方式, 而是形成一个少见的P-核苷酸, 可能是为了避免DNA瞎链接吧. 同时在重排连接时,是通过倒转方式相连接。其实我也不懂这个倒转,小声BB. 不过这个方式保证了重组的准确,避免了出错. 这就是生命的奥秘啊.
免疫组库测序
作为适应性免疫的关键细胞效应物,T和B淋巴细胞利用专门的抗体来识别抗原,响应和中和各种外在威胁。这些受体(B淋巴细胞中的免疫球蛋白,T淋巴细胞中的T细胞受体)具有令人难以置信的变异. 免疫系统依赖于免疫细胞的多样化过程,其在B细胞免疫球蛋白(也是B细胞受体BCR)和T细胞受体(TCR)中产生巨大的序列变异。这些大量但具有不同免疫受体和抗原特异性的淋巴细胞, 在识别出它们的特异性抗原后,淋巴细胞可以通过适当的病原体靶向效应物和随后的记忆功能进行克隆扩增。
虽然功能不同,但BCR和TCR的组织相似且相应多样。两者都由两个不同的亚基链组成,每个链含有可变结构域,该可变结构域有助于异二聚体受体的抗原结合表面。编码这些可变结构域的基因的多样性机制我们已经在之前的[部分](# section-01)讲过了.
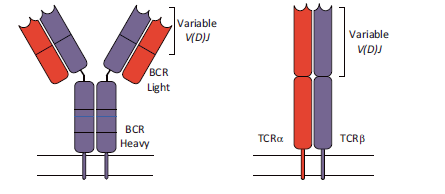
免疫细胞具有复杂的遗传多样化机制的产物。高通量测序(NGS)技术的最新进展已经改变了我们对核酸检测方式, 以及最近的单细胞分辨率下检测抗原受体库的能力都使这一领域突飞猛进.
但是尽管RNA-Seq或基因组重测序等高通量测序技术应用已经流程化和标准化,但免疫库的高通量测序并没有“一刀切”的方法.
免疫组测序的选择
目前主流的大多数方法只是针对针对单个亚基(通常是BCR重链,TCR a或TCR b链)。同时目前测序的区域主要集中在CDR3区, 这是因为目前最主流的测序平台illumina的最大读长是PE250, 也就是只能测通500bp的片段长短. 而一个全长的轻链和重链都不至于于此.
但是, CDR3靶向策略可能不适用于某些应用,例如检查完整的SHM谱和/或大量突变的BCR.虽然CDR3是作用最关键的区域, 并且在J片段的上游和V区的下游涉及引物可以避免来自染色体上的非重组序列的污染. 但是还是读长太短了,得不到完整的全长序列.
HTS数据集中非生产性序列的存在对于研究淋巴细胞发育中的受体多样化和选择可能是有利的. 但还是造成PCR构建文库的困难性。 当RNA用作输入材料时. 此外,PCR扩增的困难度下降了。同时高度表达的TCR和BCR RNA转录本也比其在DNA中丰富得多,但是RNA的定量可能受不同细胞中BCR 和TCR 总转录本丰度的影响。另一个主要需要注意的是测序文库的核酸类型:基因组DNA还是转录物RNA。基因组DNA文库通常包含所有V-D-J受体重组体,无论它们是否最终编码成蛋白。
免疫组学的主要挑战
主要是来自, 需要对目标区域的序列进行多重PCR, 这一步说起来不难, 但是做起来需要考虑的点很多. 可以说免疫组的主要的挑战就来PCR策略的设计.
需要对极其可变的模板混合物进行全面和无偏差的扩增。扩增偏差对于NGS定量影响巨大,因为不均匀的扩增效率会使克隆频率测量偏差。
目前常常采用多重PCR,其中正向引物与V区段互补。反向引物设计在J区段或恒定区外显子。此外,还有格各式各样的其他方法[1]. 但测序的区域都是CDR3区域为主.
免疫组分析的内容
第一步肯定是数据处理,其中对原始序列读取进行过滤,组装和纠正错误; 和数据分析,因项目而异。这一步虽然不是分析的主要障碍,但序列错误可能会混淆测量再生多样性; 如果没有适当的校正,影响还是挺大的.
同时,因为多重PCR可能引入的扩增偏差. 免疫组测序通常会在扩增之前将随机序列“条形码”(UMI)附加到PCR产物中。后续可以用于定量分析.
鉴定抗原受体序列中存在的V,D和J区段是许多分析工作流程中常见的第一步,也就是所谓V-D-J分配和CDR3注释. 一般而言,VDJ分类工具通过NCBI 或IMGT 数据库来进行比对识别.
接着就会研究lymphocyte subsets(这个不知道怎么翻译), 先称之为免疫单元吧, 不过概念好理解, 就是测序的片段, 一个片段就可以认为是一个免疫细胞. 类似于扩增子测序, 会研究免疫单元的丰富度和多样性, 还会研究种类和样本的分布等等. 感觉和16s非常相似.
16s就有, 物种定量, a多样性, b多样性, 功能注释等等. 免疫组测序也有对应的分析内容. 关于这部分的详细分析内容. 会在
应用方向
免疫的动态变化: 免疫库不仅是给某一瞬时的免疫应答拍快照,更是可以研究生物体遇到外来抗原的个体史。在免疫系统处理了特定的威胁之后,如果另一个相同的威胁在未来升高,那么记忆细胞就会发展出来。可以通过用下一代测序分析免疫系统来研究这种免疫记忆。NGS的超高分辨率允许寻找表明暴露于病毒,真菌,其他感染因子或与自身免疫疾病相关的特定序列.
免疫谱的差异状态调查: 可以设置比较组, 关注不同时间点. 或者不同状态和处理下的对照组与处理组之间的差异.
医疗状态 : 抗体或T细胞库的高分辨率表征同样支持新疗法和诊断的开发。通过NGS分析抗原受体支持新抗体的鉴定或开发可引发足够免疫原性的有效疫苗和佐剂制剂。此外,通过新一代测序的免疫分析在治疗性抗体,免疫疗法,疫苗或诊断的研究和开发中是非常宝贵的参考。

参考文献:
[1] Calis, J. J. A., & Rosenberg, B. R. (2014). Characterizing immune repertoires by high throughput sequencing: Strategies and applications. Trends in Immunology, 35(12), 581–590. https://doi.org/10.1016/j.it.2014.09.004
[2] 【科普】B细胞的养成之路(二). (不详). 取读于 2019年6月25日, 从 知乎专栏 website: https://zhuanlan.zhihu.com/p/32448578
[3] 【科普】B细胞的养成之路(一). (不详). 取读于 2019年6月25日, 从 知乎专栏 website: https://zhuanlan.zhihu.com/p/32448545
[4] 免疫库谱测序| ArcherDX. (不详). 取读于 2019年6月25日, 从 https://archerdx.com/immunoverse
[5] AptaIT GmbH | Sequence analysis software for BCR profiling and antibody identification. (不详). 取读于 2019年6月25日, 从 aptait website: https://ngsdataanalysis.com/software/bcr/
[6] High-Definition Immunology. (2017, 六月 14). 取读于 2019年6月25日, 从 GEN - Genetic Engineering and Biotechnology News website: https://www.genengnews.com/uncategorized/high-definition-immunology/
[7] Ye, B., Smerin, D., Gao, Q., Kang, C., & Xiong, X. (2018a). High-throughput sequencing of the immune repertoire in oncology: Applications for clinical diagnosis, monitoring, and immunotherapies. Cancer Letters, 416, 42–56. https://doi.org/10.1016/j.canlet.2017.12.017
[8] Ye, B., Smerin, D., Gao, Q., Kang, C., & Xiong, X. (2018b). High-throughput sequencing of the immune repertoire in oncology: Applications for clinical diagnosis, monitoring, and immunotherapies. Cancer Letters, 416, 42–56. https://doi.org/10.1016/j.canlet.2017.12.017